“She can’nae take anymore, Captain!!” shouts Scotty as he enters my office. “The system is overloaded because of the number of new customers sales have managed to make this quarter” - “I know” I reply, “Datadog just alerted me via pager-duty - but there is little we can do at the moment, were scaled out to the limit we are allowed and we will have to ask management for more resources”.
Engineers in a micro-service based eco-system have all experienced the above scenario more than once. It’s not pleasant when you are the one in the eye of the storm - but what can we do to help ameliorate the scenario.
What is an Adaptive System
According to Wikipedia an adaptive system is ‘a set of interacting or interdependent entities, real or abstract, forming an integrated whole that together are able to respond to environmental changes or changes in the interacting parts’. From a micro-service architecture this can mean that the application - a collection of web-services and apps - or the individual service themselves react and adapt to changes in the environment.
What we are NOT referring to here is what the application actually designed to do - user management or hotel room booking for example. What we ARE referring to is adapting to changes based upon CPU load, Disc usage, network usage, service availability amongst others.
Adaptive system behavior can occur at two main levels: macro and the micro level. Macro level adaptation occurs at at about systems/application level (multi-service or multi-service-instance). It at this level, if you are using docker and kubernetes (who isn’t these days) where an individual service is at ‘stress’ under high system load you scale out automatically horizontally. Kubernetes is excellent at this systems level monitoring and management of instances.
Micro level adaptation occurs within an individual micro-service and where sensors to hook into host information are linked into the service (a bit like and organ or cell within an animal) itself. Common ‘sensors’ are for CPU load, disk usage/availability and network bandwidth/usage for example; but you could also have ‘sensors’ which access information/data from a central management system or dashboard for more broad level effects.
An obvious question is what do we do with this ability to sense our environment at the micro level? - what does it give us the humble developer or company? Those questions take a bit more consideration and are highly dependant on your application and deployment model. A good start is to develop a number of stress scenarios in conjunction with the Quality, development and systems architecture teams. You need to have plans of what you need to do and how to react when the tornado happens - and it WILL happen - and what other downstream services your service interacts with. Often this plan comes down to making sure you have provisioned enough instances (in the right geographic locations) and allocated enough disc storage etc. From an adaptive microservice perspective a good question to ask ‘is it possible for an individual service help ameliorate things when it itself is ‘stressed’?
Lets take a step back and think about web-services. In an ideal world a web-service does only one things and has no down-stream dependencies - but most web-services usually have at least one downstream dependency; This could be a database, kafka/JMS queue or calls to other web-services. What happens when one of these services go down or are stressed? This is where often you implement a ‘circuit breaker pattern’ using something like hystrix and this is an example of micro-level adaptive behavior which reacts to network related problems other possible behaviors are:
- Dynamically change the amount of logging done based on system or disc load. Less logging when system is under stress, more when load is light.
- Not all downstream dependencies/calls are actually necessary (though might be nice to have). Stop doing (or postpone) ones that are not necessary when the system is under stress. This obviously has to be understood and agreed by all the stake holders.
- Start rejecting calls when things get stressed. This could be all or a variable percentage of the calls. You could link this with a load balancer which redirects calls to another instance if the original target service returns an overload error.
There are many things that are possible and appropriate for the system and user. A good starting place is to go through a service line by line and call by call and ask:
- Is this call necessary at all - if not you might be able to remove it completely.
- If this call is necessary … is it necessary when the system is under stress or overload? Could it be dropped or postponed (an example is a scheduled task or an ‘informational’ call to another system)?
It might help if you define a number of scenarios: ’normal usage’, ’elevated usage’ and ‘overload usage’. The answers can then be distilled into a strategy which can be implemented.
Lets take and develop a simple - if contrived - web-service and put this into an action and see where it can lead us.
A Simple Example of a Local Adaptive System
We have a simple web-service which reacts to rest api call makes a down-stream or complicated calculation, logs some stuff and then makes an ‘informational FYI’ down-stream call to another system before returning. For simplicity sake the ’essential’ complicated call will always take 200ms and the ‘informational’ call will always take 50ms; and we will count the number of time each step takes.
The full maven java project can be found on github here.
The ‘basic’ non-adaptive endpoint is covered by this code snapshot:
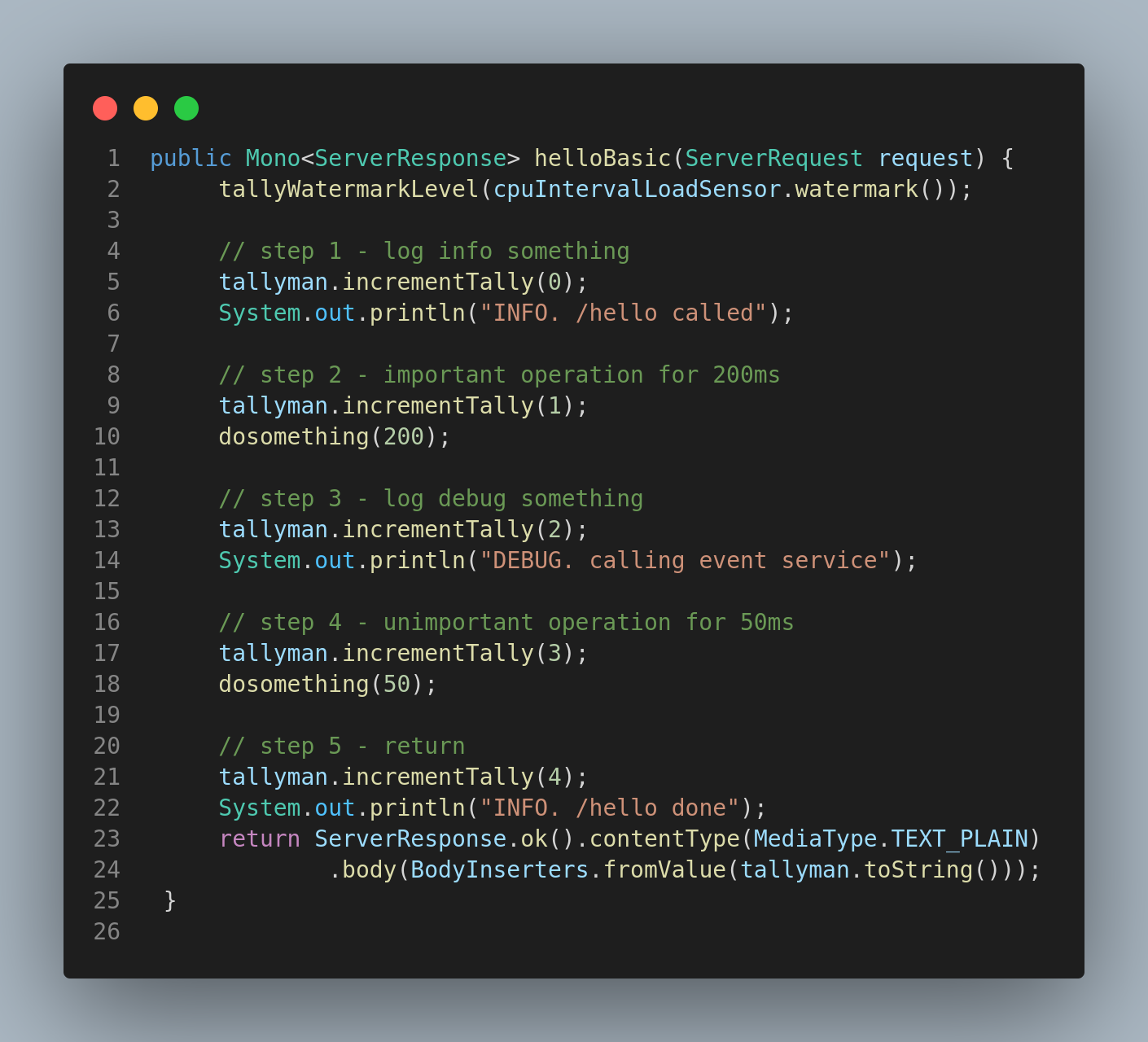
Going though this we define based off of the CPU load where the service instance is running the following three scenarios:
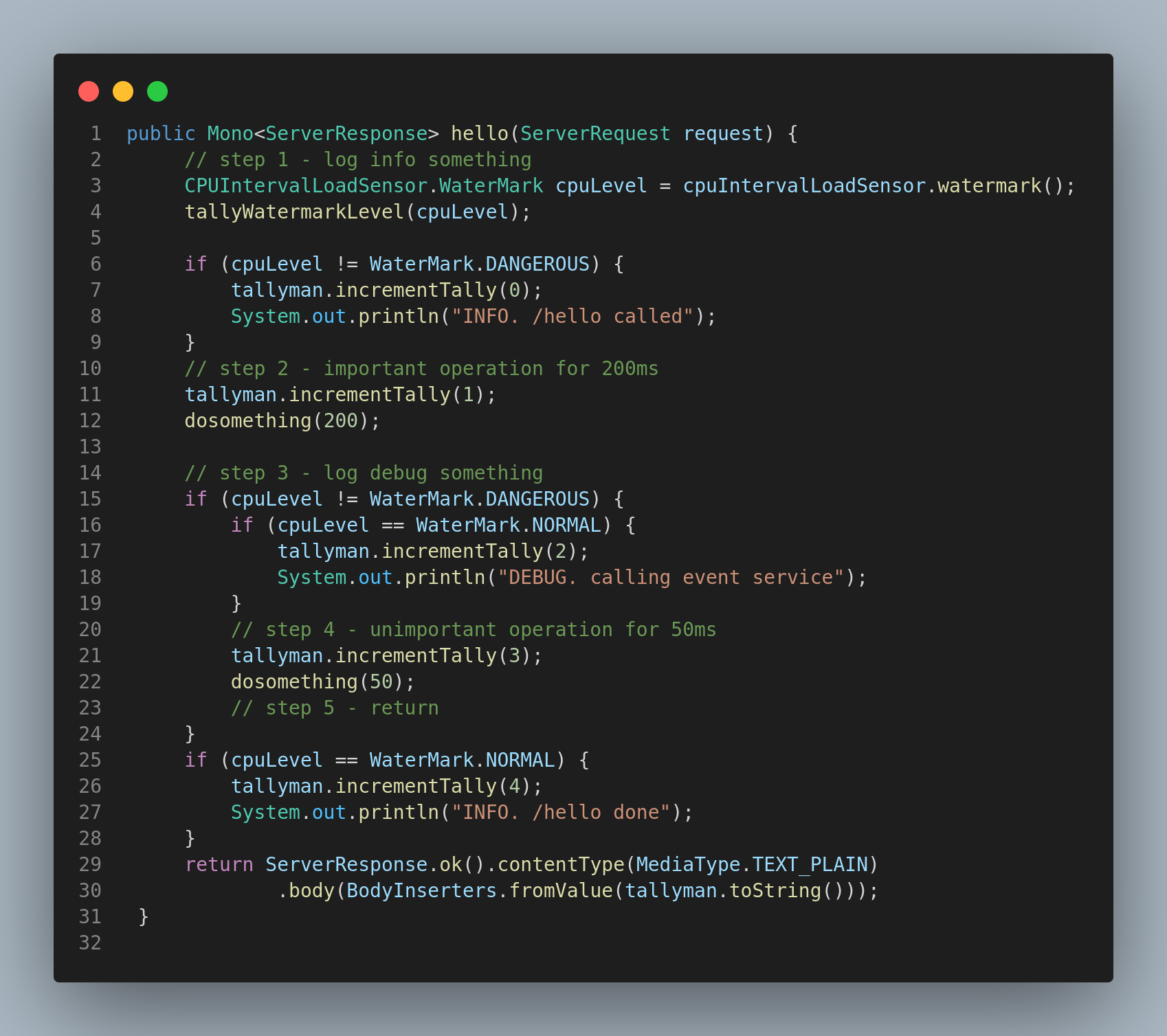
- NORMAL When CPU load is 50% or less - and we will do all the logging and make all the ‘informational’ down-stream calls.
- WARNING When CPU load is between 50% and 80% - and we will drop most of the logging but still keep the ‘informational’ down-stream calls.
- DANGEROUS When CPU load is 80% or more - in this scenario we will stop logging as well as dropping the ‘informational’ down-stream calls.
This version of the original call can (in a crude way) defined by the following code snapshot:
We then built and deployed the application (the adaptive and non-adaptive versions are deployed as different rest end points in the same service). The testing methodology is simple: Call each endpoint under different load scenarios (number of concurrent callers calling as fast as they can) for a minute and track the call RPS and CPU usage. The Bombardier load tool would provide the stress and yield the throughput in requests-per-second and the service itself has a background thread which dumps the cpu load and the number of calls at each step. Each load test was run for 60 seconds with gaps between tests to all CPU to go back to a normal low level.
Test Results
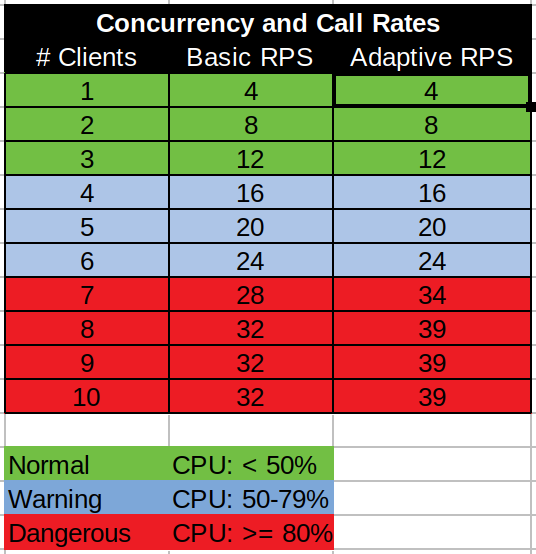
So with two clients the basic endpoint can process 8 requests/second and the adaptive one the same.
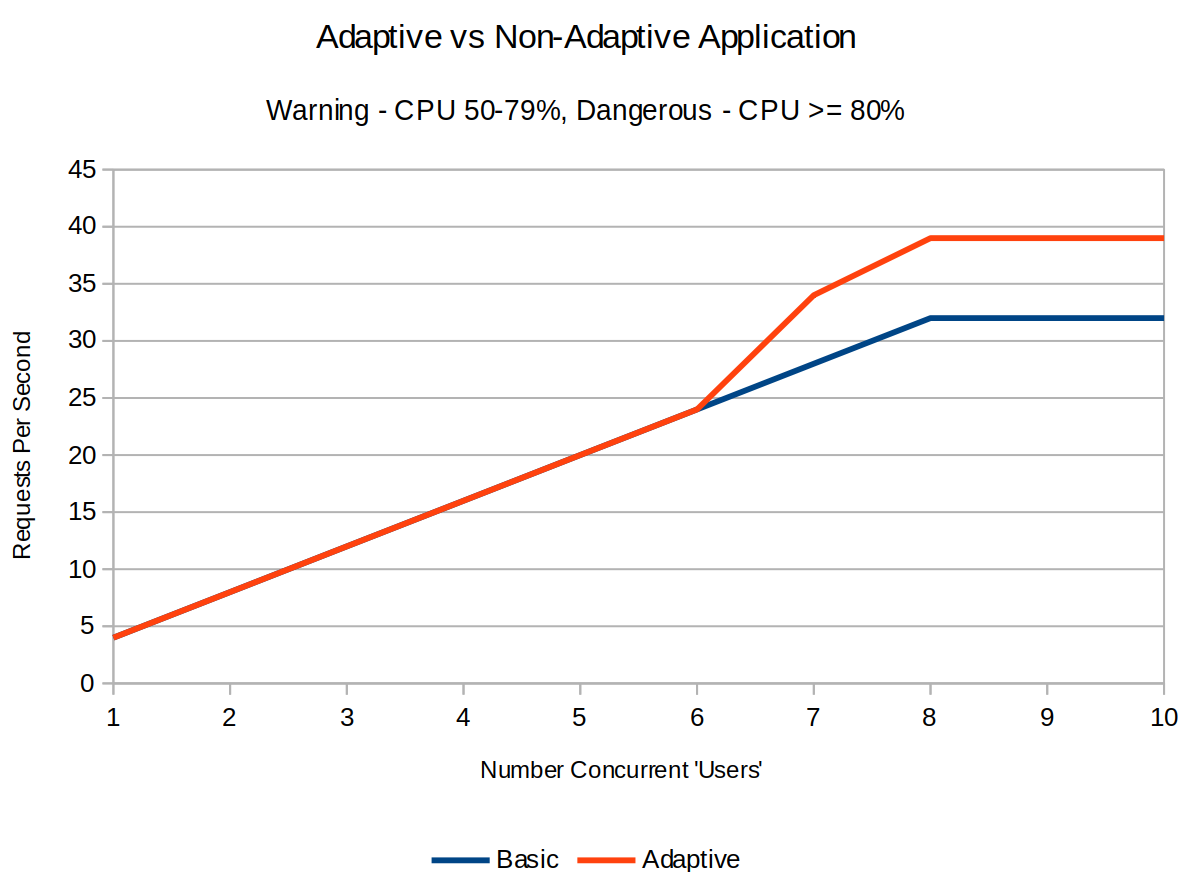
The table and graph shows pretty much the same behavior until the system load reaches 80% where upon the adaptive endpoint stops making the ‘informational’ call. This free’s up CPU cycles for the adaptive endpoint to use to process more of the requests coming in AND still do more of the ‘important’ stuff.
Naturally a services level of ability to adapt and ‘mileage for applicability’ will vary from service to service and domain to domain - but it is something to think about.